When it comes to indexing in a Neo4j graph database, different options exist for a developer to create and maintain the index.
In the following short examples I’d like to demonstrate different possibilities for index management.

Dependencies
Only one dependency is needed to run the following examples and start an embedded neo4j server – I’m using Gradle here to manage my dependencies but Maven, Ivy, SBT should work without a problem, too.
This is my build.gradle - I have added the application plugin to execute the different Java code samples.
__
apply plugin: 'java'
apply plugin: 'eclipse'
apply plugin:'application'
mainClassName = System.getProperty("mainClass")
sourceCompatibility = 1.8
version = '1.0.0'
jar {
manifest {
attributes 'Implementation-Title': 'hasCode.com - Neo4j Indexing Strategy Tutorial', 'Implementation-Version': version
}
}
repositories {
mavenCentral()
}
dependencies {
compile 'org.neo4j:neo4j:2.1.6'
}Domain Model
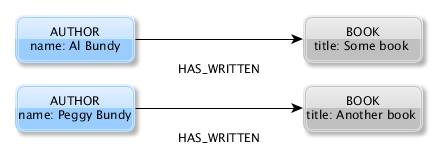
This is our simple domain model – there are authors and books. An author has a name property, a book has a title property and an author has zero or more relations of type HAS_WRITTEN to a book.
I’ve used the yed editor to model the following visualization:
The following general Cypher queries allow us to query for Al’s and Peggy’s books:
Books by Al Bundy:
MATCH (author:AUTHOR{name : 'Al Bundy'})-[:HAS_WRITTEN]->(book:BOOK)
RETURN author, bookBooks by Peggy Bundy:
MATCH (author:AUTHOR{name : 'Peggy Bundy'})-[:HAS_WRITTEN]->(book:BOOK)
RETURN author, bookLabels
The following two custom labels help us to mark authors and books:
package com.hascode.tutorial.label;
import org.neo4j.graphdb.Label;
public enum CustomLabels implements Label {
AUTHOR, BOOK
}Relations
This is our specialized relation HAS_WRITTEN:
package com.hascode.tutorial.relation;
import org.neo4j.graphdb.RelationshipType;
public enum CustomRelations implements RelationshipType {
HAS_WRITTEN
}Indexing Strategies
In the following examples, we’re going to take a look at three different possibilities for index management: manual, schema-based and automatic indexing.
Manual Indexing
Manual indexing burdens the developer with creating or updating index entries for new nodes by hand when necessary.
The IndexManager allows us to get a reference to a specialized index (in the following example named “authors” and “books“) and add new index entries there for a node.
Our final Cypher queries to search for books by two different authors is written using a legacy index lookup: START author=node:authors(name = ‘Peggy Bundy’) for the purpose of demonstration.
package com.hascode.tutorial.examples;
import java.io.IOException;
import java.nio.file.Files;
import org.neo4j.cypher.javacompat.ExecutionEngine;
import org.neo4j.cypher.javacompat.ExecutionResult;
import org.neo4j.graphdb.GraphDatabaseService;
import org.neo4j.graphdb.Node;
import org.neo4j.graphdb.Transaction;
import org.neo4j.graphdb.factory.GraphDatabaseFactory;
import org.neo4j.graphdb.index.Index;
import org.neo4j.graphdb.index.IndexManager;
import com.hascode.tutorial.label.CustomLabels;
import com.hascode.tutorial.relation.CustomRelations;
public class ManualIndexingExample {
public static void main(final String[] args) throws IOException {
GraphDatabaseService db = new GraphDatabaseFactory().newEmbeddedDatabase(Files.createTempDirectory("graphdb-").toString());
try (Transaction tx = db.beginTx()) {
IndexManager indexManager = db.index();
Node book1 = db.createNode(CustomLabels.BOOK);
book1.setProperty("title", "Some book");
Node book2 = db.createNode(CustomLabels.BOOK);
book2.setProperty("title", "Another book");
Index<Node> bookIndex = indexManager.forNodes("books");
bookIndex.add(book1, "title", "Some book");
bookIndex.add(book2, "title", "Another book");
Node author1 = db.createNode(CustomLabels.AUTHOR);
author1.setProperty("name", "Al Bundy");
Node author2 = db.createNode(CustomLabels.AUTHOR);
author2.setProperty("name", "Peggy Bundy");
Index<Node> authorIndex = indexManager.forNodes("authors");
authorIndex.add(author1, "name", "Al Bundy");
authorIndex.add(author2, "name", "Peggy Bundy");
author1.createRelationshipTo(book1, CustomRelations.HAS_WRITTEN);
author2.createRelationshipTo(book2, CustomRelations.HAS_WRITTEN);
ExecutionEngine engine = new ExecutionEngine(db);
// query for books written by Al Bundy
String cql1 = "START author=node:authors(name = 'Al Bundy') MATCH (author)-[:HAS_WRITTEN]->(book:BOOK) RETURN author, book";
ExecutionResult result1 = engine.execute(cql1);
System.out.println(result1.dumpToString());
// query for books written by Peggy Bundy
String cql2 = "START author=node:authors(name = 'Peggy Bundy') MATCH (author)-[:HAS_WRITTEN]->(book:BOOK) RETURN author, book";
ExecutionResult result2 = engine.execute(cql2);
System.out.println(result2.dumpToString());
tx.success();
}
}
}Running the code yields the following result:
gradle run -DmainClass=com.hascode.tutorial.examples.ManualIndexingExample
+-------------------------------------------------------+
| author | book |
+-------------------------------------------------------+
| Node[2]{name:"Al Bundy"} | Node[0]{title:"Some book"} |
+-------------------------------------------------------+
1 row
+-------------------------------------------------------------+
| author | book |
+-------------------------------------------------------------+
| Node[3]{name:"Peggy Bundy"} | Node[1]{title:"Another book"} |
+-------------------------------------------------------------+
1 rowSchema Indexing
Neo4j is a schema-optional graph database but when using a schema, the schema manager allows us to get a handle on our label indexes and to specify on which property’s change the index is updated automatically.
An example: db.schema().indexFor(CustomLabels.AUTHOR).on(“name”).create() configures the database to create or update an entry in the index for authors when a node’s name property has changed.
For more detailed information please feel free to consult the Neo4j documentation here.
package com.hascode.tutorial.examples;
import java.io.IOException;
import java.nio.file.Files;
import org.neo4j.cypher.javacompat.ExecutionEngine;
import org.neo4j.cypher.javacompat.ExecutionResult;
import org.neo4j.graphdb.GraphDatabaseService;
import org.neo4j.graphdb.Node;
import org.neo4j.graphdb.Transaction;
import org.neo4j.graphdb.factory.GraphDatabaseFactory;
import com.hascode.tutorial.label.CustomLabels;
import com.hascode.tutorial.relation.CustomRelations;
public class SchemaIndexingExample {
public static void main(final String[] args) throws IOException {
GraphDatabaseService db = new GraphDatabaseFactory().newEmbeddedDatabase(Files.createTempDirectory("graphdb-").toString());
try (Transaction tx = db.beginTx()) {
db.schema().indexFor(CustomLabels.AUTHOR).on("name").create();
db.schema().indexFor(CustomLabels.BOOK).on("title").create();
tx.success();
}
try (Transaction tx = db.beginTx()) {
Node book1 = db.createNode(CustomLabels.BOOK);
book1.setProperty("title", "Some book");
Node book2 = db.createNode(CustomLabels.BOOK);
book2.setProperty("title", "Another book");
Node author1 = db.createNode(CustomLabels.AUTHOR);
author1.setProperty("name", "Al Bundy");
author1.createRelationshipTo(book1, CustomRelations.HAS_WRITTEN);
Node author2 = db.createNode(CustomLabels.AUTHOR);
author2.setProperty("name", "Peggy Bundy");
author2.createRelationshipTo(book2, CustomRelations.HAS_WRITTEN);
tx.success();
}
try (Transaction tx = db.beginTx()) {
ExecutionEngine engine = new ExecutionEngine(db);
// query for books written by Al Bundy (using a query hint for index
// selection)
String cql1 = "MATCH (author:AUTHOR)-[:HAS_WRITTEN]->(book:BOOK) USING INDEX author:AUTHOR(name) WHERE author.name='Al Bundy' RETURN author, book";
ExecutionResult result1 = engine.execute(cql1);
System.out.println(result1.dumpToString());
// query for books written by Peggy Bundy (using a query hint for
// index selection)
String cql2 = "MATCH (author:AUTHOR)-[:HAS_WRITTEN]->(book:BOOK) USING INDEX author:AUTHOR(name) WHERE author.name='Peggy Bundy' RETURN author, book";
ExecutionResult result2 = engine.execute(cql2);
System.out.println(result2.dumpToString());
tx.success();
}
}
}Running the code yields the following result:
gradle run -DmainClass=com.hascode.tutorial.examples.SchemaIndexingExample
+-------------------------------------------------------+
| author | book |
+-------------------------------------------------------+
| Node[2]{name:"Al Bundy"} | Node[0]{title:"Some book"} |
+-------------------------------------------------------+
1 row
+-------------------------------------------------------------+
| author | book |
+-------------------------------------------------------------+
| Node[3]{name:"Peggy Bundy"} | Node[1]{title:"Another book"} |
+-------------------------------------------------------------+
1 rowAutomatic Indexing
Automatic indexing is by default turned off for both, nodes and relations but it may be turned on by container configuration.
The configuration needed for an embedded neo4j database follows in the example below, when using a standalone server, you should add the following lines to the configuration file e.g. $NEO4J_SERVER/conf/neo4j.properties:
node_auto_indexing=true
node_keys_indexable=name,titleFor more detailed information about automatic indexing, please feel free to take a look at the Neo4j documentation here.
package com.hascode.tutorial.examples;
import java.io.IOException;
import java.nio.file.Files;
import org.neo4j.cypher.javacompat.ExecutionEngine;
import org.neo4j.cypher.javacompat.ExecutionResult;
import org.neo4j.graphdb.GraphDatabaseService;
import org.neo4j.graphdb.Node;
import org.neo4j.graphdb.Transaction;
import org.neo4j.graphdb.factory.GraphDatabaseFactory;
import org.neo4j.graphdb.factory.GraphDatabaseSettings;
import org.neo4j.graphdb.index.AutoIndexer;
import org.neo4j.graphdb.index.IndexHits;
import com.hascode.tutorial.label.CustomLabels;
import com.hascode.tutorial.relation.CustomRelations;
public class AutoIndexingExample {
public static void main(final String[] args) throws IOException {
GraphDatabaseService db = new GraphDatabaseFactory().newEmbeddedDatabaseBuilder(Files.createTempDirectory("graphdb-").toString())
.setConfig(GraphDatabaseSettings.node_keys_indexable, "name, title").setConfig(GraphDatabaseSettings.node_auto_indexing, "true").newGraphDatabase();
try (Transaction tx = db.beginTx()) {
Node book1 = db.createNode(CustomLabels.BOOK);
book1.setProperty("title", "Some book");
Node book2 = db.createNode(CustomLabels.BOOK);
book2.setProperty("title", "Another book");
Node author1 = db.createNode(CustomLabels.AUTHOR);
author1.setProperty("name", "Al Bundy");
author1.createRelationshipTo(book1, CustomRelations.HAS_WRITTEN);
Node author2 = db.createNode(CustomLabels.AUTHOR);
author2.setProperty("name", "Peggy Bundy");
author2.createRelationshipTo(book2, CustomRelations.HAS_WRITTEN);
ExecutionEngine engine = new ExecutionEngine(db);
// query for books written by Al Bundy
String cql1 = "START author=node:node_auto_index(name='Al Bundy') MATCH (author)-[:HAS_WRITTEN]->(book) RETURN author, book";
ExecutionResult result1 = engine.execute(cql1);
System.out.println(result1.dumpToString());
// query for books written by Peggy Bundy
String cql2 = "START author=node:node_auto_index(name='Peggy Bundy') MATCH (author)-[:HAS_WRITTEN]->(book) RETURN author, book";
ExecutionResult result2 = engine.execute(cql2);
System.out.println(result2.dumpToString());
tx.success();
// query programmatically
AutoIndexer<Node> autoIndexer = db.index().getNodeAutoIndexer();
IndexHits<Node> alBundy = autoIndexer.getAutoIndex().get("name", "Al Bundy");
System.out.println("search from auto indexer returned: " + alBundy.getSingle().getProperty("name"));
}
}
}Running the code yields the following result:
gradle run -DmainClass=com.hascode.tutorial.examples.AutoIndexingExample
+-------------------------------------------------------+
| author | book |
+-------------------------------------------------------+
| Node[2]{name:"Al Bundy"} | Node[0]{title:"Some book"} |
+-------------------------------------------------------+
1 row
+-------------------------------------------------------------+
| author | book |
+-------------------------------------------------------------+
| Node[3]{name:"Peggy Bundy"} | Node[1]{title:"Another book"} |
+-------------------------------------------------------------+
1 row
search from auto indexer returned: Al BundyTutorial Sources
Please feel free to download the tutorial sources from my GitHub repository, fork it there or clone it using Git:
git clone https://github.com/hascode/neo4j-indexing-strategy-tutorial.git