Developing plugins for the Confluence Wiki a developer sometimes needs to save additional metadata to a page object using Bandana or the ContentPropertyManager. Wouldn’t it be nice if this metadata was available in the built-in Lucene index?
That is were the Confluence Extractor Module comes into play..
Overview
An extractor allows the developer to add new fields to the lucene search index. Creating a new extractor is quite simple – just implement the interface com.atlassian.bonnie.search.Extractor or bucket.search.lucene.extractor.BaseAttachmentContentExtractor if you want to build a new file extractor.
There is a good documentation for both extractor types available at the Atlassian Wiki.
Example Application
The following demonstration plugin adds a new field “hascode” to the lucene search index, appends it to every existing page and fills the field with a string “XXX”. Maven archetypes are used for the tutorial – if you need some help on this topic – please take a look at this article.
-
Create a new Maven project using archetypes in your IDE or like by console (always use plugin type 2!):
mvn archetype:generate -DarchetypeCatalog=http://svn.atlassian.com/svn/public/atlassian/maven-plugins/archetype-catalog -
That’s my pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <parent> <groupId>com.atlassian.confluence.plugin.base</groupId> <artifactId>confluence-plugin-base</artifactId> <version>25</version> </parent> <modelVersion>4.0.0</modelVersion> <groupId>com.hascode.confluence.plugin</groupId> <artifactId>search-tutorial</artifactId> <version>0.0.1-SNAPSHOT</version> <name>hasCode.com - Confluence Search Tutorial</name> <packaging>atlassian-plugin</packaging> <properties> <atlassian.plugin.key>com.hascode.confluence.plugin.search-tutorial</atlassian.plugin.key> <!-- Confluence version --> <atlassian.product.version>3.0</atlassian.product.version> <!-- Confluence plugin functional test library version --> <atlassian.product.test-lib.version>1.4.1</atlassian.product.test-lib.version> <!-- Confluence data version --> <atlassian.product.data.version>3.0</atlassian.product.data.version> </properties> <description>hasCode.com - Confluence Search Tutorial</description> <url>https://www.hascode.com</url> </project> -
Add the plugin descriptor for the extractor module to the atlassian-plugin.xml
<atlassian-plugin key="${atlassian.plugin.key}" name="search-tutorial" pluginsVersion="2"> <plugin-info> <description>hasCode.com - Confluence Search Tutorial</description> <version>${project.version}</version> <vendor name="hasCode.com" url="https://www.hascode.com"/> </plugin-info> <extractor name="PageInformationExtractor" key="pageInformationExtractor" class="com.hascode.confluence.plugin.search_tutorial.extractor.PageExtractor" priority="1000"> <description>Adding some searchable fields for a page to the search index</description> </extractor> </atlassian-plugin> -
Creating a package com.hascode.confluence.plugin.search_tutorial.extractor and add the extractor class PageExtractor
package com.hascode.confluence.plugin.search_tutorial.extractor; import org.apache.log4j.Logger; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import com.atlassian.bonnie.Searchable; import com.atlassian.bonnie.search.Extractor; import com.atlassian.confluence.core.ContentEntityObject; public class PageExtractor implements Extractor { private final Logger logger = Logger .getLogger("com.hascode.confluence.plugin.search-tutorial"); private static final String FIELD_NAME = "hascode"; public void addFields(Document doc, StringBuffer searchableText, Searchable searchable) { if (searchable instanceof ContentEntityObject) { String info = "XXX"; searchableText.append(info).append(" "); doc.add(new Field(FIELD_NAME, info, Field.Store.YES, Field.Index.TOKENIZED)); } else { logger.debug("searchable is no content entity"); } } } -
Build and deploy the plugin
mvn atlassian-pdk:install -
Open Confluence in your browser, head over to Confluence Admin > Content Indexing and rebuild the search index
-
There is a nice feature in Confluence that allows you to take a look at the indexed entries and analyze the available fields: http://localhost:8080/admin/indexbrowser.jsp
-
*Update:*___The index browser has been removed in Confluence 3.2.1 due to security issues – if you want to take a deeper look at the lucene index you should use _LUKE – the Lucene Index Toolbox – downloadable as a jar at the project’s homepage.
-
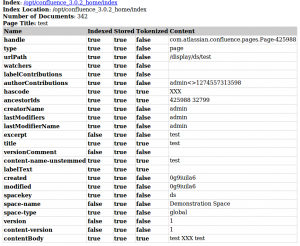
In the index browser/Luke you should be able to spot the new field “hascode” with the content “XXX” – thats how it looks like in my system
 Figure 1. confluence-lucene-field
Figure 1. confluence-lucene-field -
Now it is possible to search for the new field in the global confluence search by adding hascode:XXX as parameter
-
That’s what the search result looks like.
 Figure 2. confluence-field-search
Figure 2. confluence-field-search
Final thoughts:
A new field was added to the document/the index but in addition the field’s value was also added to the contentBody. This means that a search for “XXX” would show similar results. One should consider which behaviour is desired.
The following example adds the field “hascode” only to pages with a title containing the word “test” – this is the modified PageExtractor
package com.hascode.confluence.plugin.search_tutorial.extractor;
import org.apache.log4j.Logger;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import com.atlassian.bonnie.Searchable;
import com.atlassian.bonnie.search.Extractor;
import com.atlassian.confluence.core.ContentEntityObject;
public class PageExtractor implements Extractor {
private final Logger logger = Logger
.getLogger("com.hascode.confluence.plugin.search-tutorial");
private static final String FIELD_NAME = "hascode";
public void addFields(Document doc, StringBuffer searchableText,
Searchable searchable) {
if (searchable instanceof ContentEntityObject) {
ContentEntityObject ceo = (ContentEntityObject) searchable;
if (ceo.getTitle().matches("test")) {
String info = "XXX";
searchableText.append(info).append(" ");
doc.add(new Field(FIELD_NAME, info, Field.Store.YES,
Field.Index.TOKENIZED));
}
} else {
logger.debug("searchable is no content entity");
}
}
}I have created a page named “test” in the demonstration space – this page has the field “hascode” – take a look at the new search result:

Resources
Article Updates
-
2015-03-03: Table of contents added.