Lucene is my favourite search engine library and the more often I use it in my projects the more features or functionality I find that were unknown to me.
Two of those features I’d like to share in the following tutorial is one the one hand the possibility to specify different analyzers on a per-field basis and on the other hand the API to create a simple character based tokenizer and analyzer within a few steps.
Finally we’re going to create a small index- and search application to test both features in a real scenario.

Lucene Dependencies
Using Maven, adding the following dependencies to our pom.xml should add everything we need to run the following examples:
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queries</artifactId>
<version>${lucene.version}</version>
</dependency>Writing a custom Analyzer and Tokenizer
In the following steps we’ll be implementing a custom tokenizer and finally an analyzer using the tokenizer.
As final result we want to be able to create multiple tokens from an input string by splitting it by the character “e” and case-insensitive and in addition the character “e” should not be part of the tokens created.
Two simple examples:
-
123e456e789 → the tokens “123“, “456” and “789” should be extracted
-
123Eabcexyz → the tokens “123“, “abc” and “xyz“ should be extracted
Character based Tokenizer
To create a tokenizer to fit the scenario above is easy for us as there already exists the CharTokenizer that our custom tokenizer class may inherit.
We just need to implement one method that gets the codepoint value of the parsed character as parameter and returns whether it matches the character “e” .
Older Lucene Versions: Since Lucene 3.1 the CharTokenizer API has changed, in older versions we’re using isTokenChar(char c) instead.
package com.hascode.tutorial.index.analysis;
import java.io.Reader;
import org.apache.lucene.analysis.util.CharTokenizer;
import org.apache.lucene.util.Version;
public class ECharacterTokenizer extends CharTokenizer {
public ECharacterTokenizer(final Version matchVersion, final Reader input) {
super(matchVersion, input);
}
@Override
protected boolean isTokenChar(final int character) {
return 'e' != character;
}
}Analyzer using the custom Tokenizer
Now that we’ve got a simple tokenizer we’d like to add an analyzer using our tokenizer and making our analysis case-insensitive.
This is really easy as there already exists a LowerCaseFilter and we may assemble our solution with the following few lines of code:
package com.hascode.tutorial.index.analysis;
import java.io.Reader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.core.LowerCaseFilter;
import org.apache.lucene.util.Version;
public class ECharacterAnalyser extends Analyzer {
private final Version version;
public ECharacterAnalyser(final Version version) {
this.version = version;
}
@Override
protected TokenStreamComponents createComponents(final String field,
final Reader reader) {
Tokenizer tokenizer = new ECharacterTokenizer(version, reader);
TokenStream filter = new LowerCaseFilter(version, tokenizer);
return new TokenStreamComponents(tokenizer, filter);
}
}If we wanted to test our components built now there is a tool for this: Luke – the Lucene Index Toolbox. For further details about this topic, please feel free to skip to the appendix.
Specifying Analyzers for each Document Field
An analyzer is used when input is stored in the index and when input is processed in a search query.
Lucene’s PerFieldAnalyzerWrapper allows us to specify an analyzer for each field name and a default analyzer as a fallback.
In the following example, we’re assigning two analyzers to the fields named “somefield” and “someotherfield” and the StandardAnalyzer is used as a default for every other field not specified in the mapping.
// map field-name to analyzer
Map<String, Analyzer> analyzerPerField = new HashMap<String, Analyzer>();
analyzerPerField.put("somefield", new SomeAnalyzer());
analyzerPerField.put("someotherfield", new SomeOtherAnalyzer());
// create a per-field analyzer wrapper using the StandardAnalyzer as .. standard analyzer ;)
PerFieldAnalyzerWrapper analyzer = new PerFieldAnalyzerWrapper(
new StandardAnalyzer(version), analyzerPerField);Running the Per-Field-Analyzer and the custom Analyzer
Finally we’re ready to put everything together adding our custom analyzer and using a per-field-analyzer.
In our setup a document has three fields: author, emails, specials and each of these fields is analyzed with a different analyzer defined in the map for the PerFieldAnalyzerWrapper:
-
author: StandardAnalyzer as it is the default analyzer specified for the PerFieldAnalyzerWrapper
-
emails: The KeywordAnalyzer is used because we have assigned it for all fields named “emails”
-
specials: Our custom ECharacterAnalyzer is used because we have assigned it for fields named “specials”
package com.hascode.tutorial.index;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.core.KeywordAnalyzer;
import org.apache.lucene.analysis.miscellaneous.PerFieldAnalyzerWrapper;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
import org.apache.lucene.util.Version;
import com.hascode.tutorial.index.analysis.ECharacterAnalyser;
public class Main {
private final Version version = Version.LUCENE_48;
public void run() throws IOException {
Directory index = new RAMDirectory();
Map<String, Analyzer> analyzerPerField = new HashMap<String, Analyzer>();
analyzerPerField.put("email", new KeywordAnalyzer());
analyzerPerField.put("specials", new ECharacterAnalyser(version));
PerFieldAnalyzerWrapper analyzer = new PerFieldAnalyzerWrapper(
new StandardAnalyzer(version), analyzerPerField);
IndexWriterConfig config = new IndexWriterConfig(version, analyzer)
.setOpenMode(OpenMode.CREATE);
IndexWriter writer = new IndexWriter(index, config);
Document doc = new Document();
doc.add(new TextField("author", "kitty cat", Store.YES));
doc.add(new TextField("email", "kitty@cat.com", Store.YES));
doc.add(new TextField("email", "kitty2@cat.com", Store.YES));
doc.add(new TextField("specials", "13e12exoxoe45e66", Store.YES));
writer.addDocument(doc);
writer.commit();
writer.close();
int limit = 20;
try (IndexReader reader = DirectoryReader.open(index)) {
Query query = new TermQuery(new Term("email", "kitty@cat.com"));
printSearchResults(limit, query, reader);
query = new TermQuery(new Term("specials", "xoxo"));
printSearchResults(limit, query, reader);
query = new TermQuery(new Term("author", "kitty"));
printSearchResults(limit, query, reader);
}
index.close();
}
private void printSearchResults(final int limit, final Query query,
final IndexReader reader) throws IOException {
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs docs = searcher.search(query, limit);
System.out.println(docs.totalHits + " found for query: " + query);
for (final ScoreDoc scoreDoc : docs.scoreDocs) {
System.out.println(searcher.doc(scoreDoc.doc));
}
}
public static void main(final String[] args) throws IOException {
new Main().run();
}
}Running the application above should produce the following output:
1 found for query: email:kitty@cat.com
Document<stored,indexed,tokenized<author:kitty cat> stored,indexed,tokenized<email:kitty@cat.com> stored,indexed,tokenized<email:kitty2@cat.com> stored,indexed,tokenized<specials:13e12exoxoe45e66>>
1 found for query: specials:xoxo
Document<stored,indexed,tokenized<author:kitty cat> stored,indexed,tokenized<email:kitty@cat.com> stored,indexed,tokenized<email:kitty2@cat.com> stored,indexed,tokenized<specials:13e12exoxoe45e66>>
1 found for query: author:kitty
Document<stored,indexed,tokenized<author:kitty cat> stored,indexed,tokenized<email:kitty@cat.com> stored,indexed,tokenized<email:kitty2@cat.com> stored,indexed,tokenized<specials:13e12exoxoe45e66>>So what has happened here? We’ve specified our analyzer-mappings and we have stored a document in the search index and afterwards searched for the document respecting the details of the analyzers so that the the…
-
.. TermQuery for “kitty@cat.com” in the field “email” matched because the KeywordAnalyzer, not the StandardAnalyzer has been applied (why? have a look at Appendix B: Using the Luke Analyzer Tool).
-
.. TermQuery for “xoxo” in the field “specials” matched because our custom ECharacterAnalyzer has created matching tokens
-
.. TermQuery for “kitty” in the field “author” matched because the StandardAnalyzer has created a term “kitty” by handling whitespace characters (→ we’ve indexed “kitty cat”)
Tutorial Sources
Please feel free to download the tutorial sources from my GitHub repository, fork it there or clone it using Git:
git clone https://bitbucket.org/hascode/lucene-perfield-analyzer-tutorial.gitAppendix A: Installing/Running Luke – The Lucene Index Toolbox
Luke has moved its location a lot of times but when searching for a version that supports the latest Lucene APIs there is this project maintained by Dmitry Kan on GitHub with the following releases ready for download.
We simply just need to download the desired version and extract the runnable jar somewhere.
Afterwards we’re able to start Luke like this:
java -jar luke-with-deps-4.8.0.jarAppendix B: Using the Luke Analyzer Tool
The Analyzer plug-in for Luke by Mark Harwood allows us analyze a given text with different integrated analyzers to see which tokens are generated by each specific analyzer.
A short example: We want to store the string “kitty@cat.com” in the index analyzed (yes there are other ways – it’s just an example) and we want to search for the complete term afterwards e.g. to implement a specialized e-mail search or something like that.
Given that the Lucene standard analyzer is used and we’d like to analyze the result for this specific case we could enter the following data in the analyzer tool:

Inspecting the results we might decide to use another analyzer, the KeywordAnalyzer and the results of this analysis looks good:

Appendix C: Running Luke with custom Analyzers
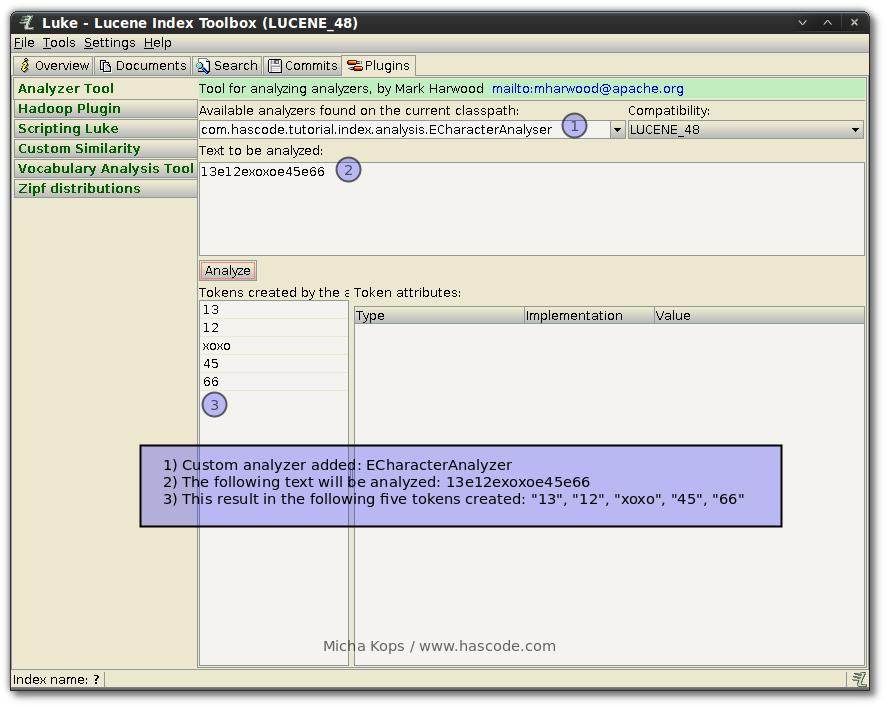
As we have written a custom analyzer we might want to analyze how some text is tokenized by this analyzer, again using Luke and the analyzer tool.
Therefore we need to add our analyzer to the class-path when running Luke – as the command line option -jar makes Java ignore class-paths set with -cp , we need to skip this option an specify the main-class to run like in the following example:
java -cp "luke-with-deps-4.8.0.jar:/path/to/lucene-per-field-analyzer-tutorial/target/lucene-perfield-analyzer-tutorial-1.0.0.jar" org.getopt.luke.LukeThis allows us to enter the full qualified name of our analyzer class in the Luke analyzer tool and run an analysis – in the following example using our ECharacterAnalyzer we’re able to verify that a given string is split by the character “e” into tokens as displayed in the following screen-shot: