| This article needs update! |
Jupyter
Installation
pip in venv
mkdir newdir && cd newdir
python -m venv .venv (1)
source .venv/bin/activate (2)
pip install jupyter numpy pandas sqlalchemy (3)
pip freeze > requirements.txt (4)
python -m jupyter lab (5)
deactivate (6)| 1 | create a new virtual environment |
| 2 | activate the environment |
| 3 | install several libraries into the activated environment |
| 4 | create a list with all dependencies install for sharing or reinstallation later |
| 5 | start jupyter |
| 6 | having finished we might want to exit the virtual environment |
(mini) conda
I’m using miniconda here and install jupyter and also some mandatory libraries like numpy and pandas:
conda install jupyter
conda install numpy
conda install pandaswe can now start jupyter by running jupyter lab or jupyter notebook.
other ways
For other installation methods like brew, pip, etc. .. see jupyter website: installation
Examples
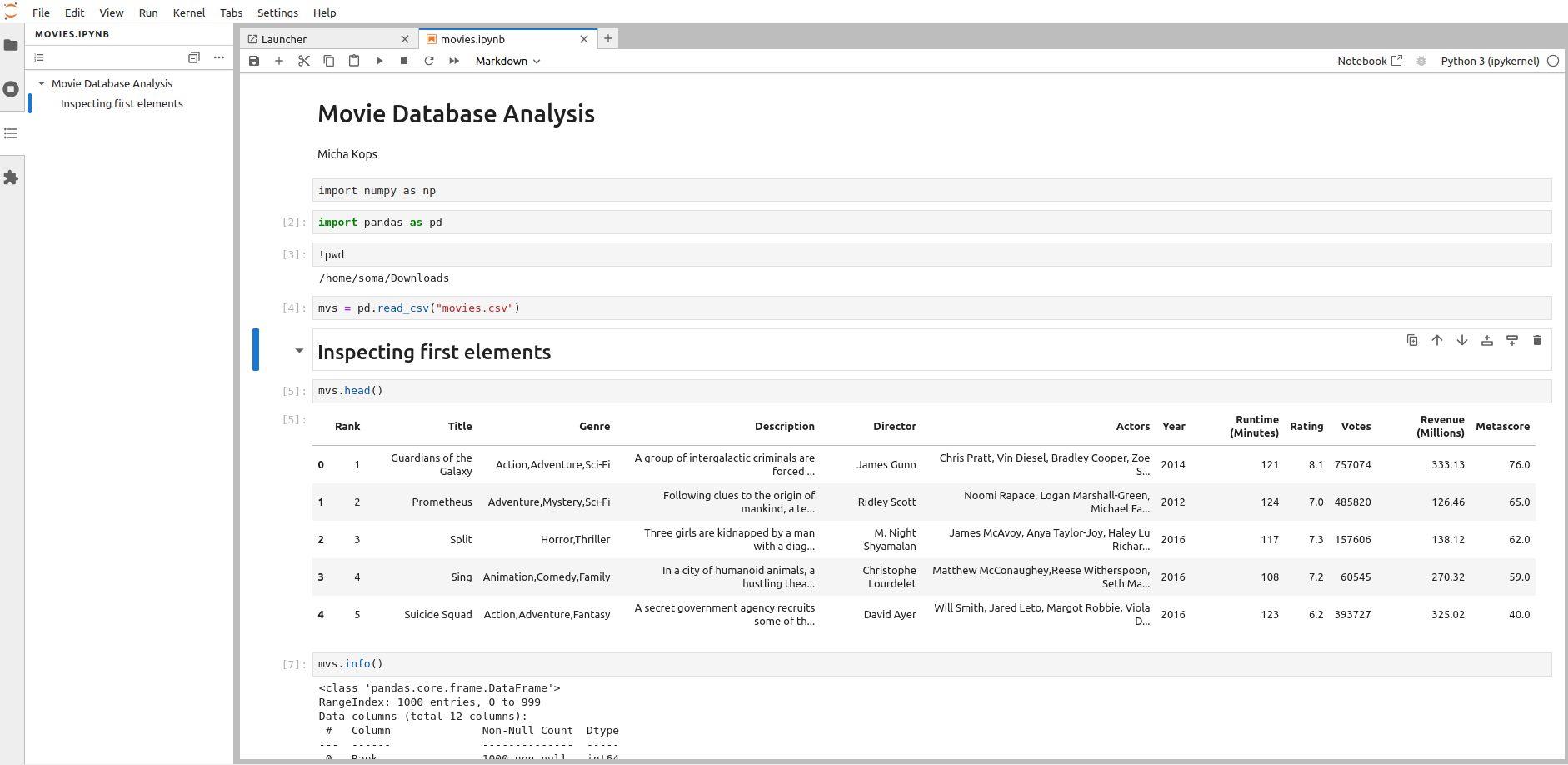
Let’s parse some movie information from the IMDB, they have put some interesting datasets online here
We’re reading in the movie.csv file and do some basic analysis like this:
reading csv files in panda
import numpy as np
import pandas as pd
mvs = pd.read_csv("movies.csv")
mvs.head()
mvs.info()
Figure 1. parsing a movie database from csv
Connecting a Postgres Database in Jupyter
install postgres library
pip install sqlalchemy
# or
conda install sqlalchemyand then in jupyter:
from sqlalchemy import create_engine
database_type='postgres'
host='somehost'
port='4432'
database_name='postgres'
user='postgres'
password='postgres'
connection_string = f"postgresql://{user}:{password}@{host}:{port}/{database_name}"
engine = create_engine(connection_string)
query = "SELECT * FROM myschema.mytable"
df = pd.read_sql(query, engine)
df.head()