Virtual Environments
Create and activate a venv
python -m venv /path/to/new-env (1)
source /path/to/new-env/bin/activate (2)| 1 | Creates a new virtual environment |
| 2 | Activate the new virtual environment |
Deactivate venv
deactivateSave used dependencies to a file
pip freeze > dependencies.txtInstall dependencies from file
pip install -r dependencies.txtStoring and fetching Credentials from the System Keyring
I am using jaraco/keyring here:
pip install keyringimport keyring
keyring.set_password("system", "db.sample.password", "xoxo")
print(keyring.get_password("system", "db.sample.password"))
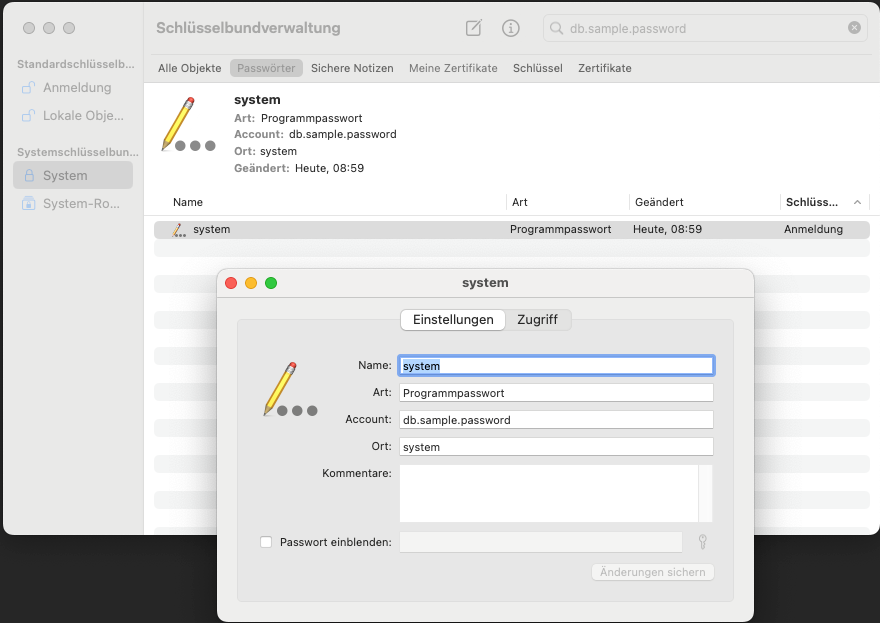
Figure 1. Our credentials in the Mac keystore
Python Data Science
For more snippets about numpy, pandas, jupyter and co., please see Python Data Science Snippets for more information.
Scripted TTS with AWS Polly and Boto3
-
Create a new speech synthesis task and wait for it to complete
-
Download the mp3 produced from S3 and purge the file from the bucket
tts_polly.py
import boto3
import time
import os
def text_to_speech(input_file, output_file, bucket_name):
polly = boto3.client('polly')
s3 = boto3.client('s3')
# Read input text
with open(input_file, 'r') as file:
text = file.read()
# Request speech synthesis
response = polly.start_speech_synthesis_task(
Text=text,
OutputFormat='mp3',
VoiceId='Joanna', # Change voice as needed
OutputS3BucketName=bucket_name
)
task_id = response['SynthesisTask']['TaskId']
print(f"Speech synthesis started with Task ID: {task_id}")
# Wait for the task to complete
while True:
status = polly.get_speech_synthesis_task(TaskId=task_id)
if status['SynthesisTask']['TaskStatus'] == 'completed':
s3_key = status['SynthesisTask']['OutputUri'].split('/')[-1]
break
elif status['SynthesisTask']['TaskStatus'] == 'failed':
print("Speech synthesis failed.")
return
time.sleep(2)
# Download the MP3 file
local_path = os.path.join(os.getcwd(), output_file)
s3.download_file(bucket_name, s3_key, local_path)
print(f"File downloaded: {local_path}")
# Delete from S3
s3.delete_object(Bucket=bucket_name, Key=s3_key)
print("File deleted from S3.")
if __name__ == "__main__":
INPUT_FILE = "input.txt" # Change to your input file
OUTPUT_FILE = "output.mp3" # Output file name
BUCKET_NAME = "your-s3-bucket-name" # Change to your S3 bucket
text_to_speech(INPUT_FILE, OUTPUT_FILE, BUCKET_NAME)